

Blog
The Evolution of Flashpoint’s Data Pipeline
An Flashpoint engineering story



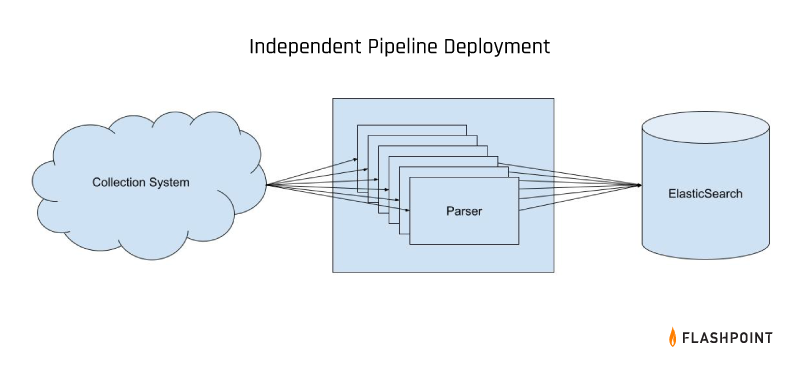
Beginnings: Individual pipelines, successes and trade-offs
The Flashpoint data pipeline was in its infancy four years ago. The engineering team published and developed datasets independently. For a spell, this worked well because we could develop rapidly and without stepping on the toes of the other teams. And, if anything went wrong, each team could respond independently.
The trade-off, however, was a duplicated effort.
Every new dataset required the engineering team to build out a full new pipeline while each individual team needed to allocate one person to become familiar with that particular—and entirely separate—pipeline deployment process.
Similarly, that independence also meant that communicating lessons learned or improvements from one pipeline to another was done on an ad hoc basis, requiring cross-team coordination for consistent deployments. Finally, it meant that there was no clear path for cross-dataset analysis or enrichment.
Selecting tools to aid our data evolution
The prospect of cross-dataset analysis was the initial impetus to build a fully streaming ETL pipeline through which all of our data would travel. This allowed us to perform transformations individually or across datasets, and to easily load data into any current or future data stores with minimal additional effort.
We also wanted the ability to load or reload historical data in batches on-demand and to dynamically scale our streaming jobs based on the amount of data flowing into them. To that end, we elected to use Apache Beam running on Google Cloud’s Dataflow Runner which, in addition to satisfying our requirements, was tightly integrated with Google Cloud services like PubSub, BigTable, and Cloud Storage.
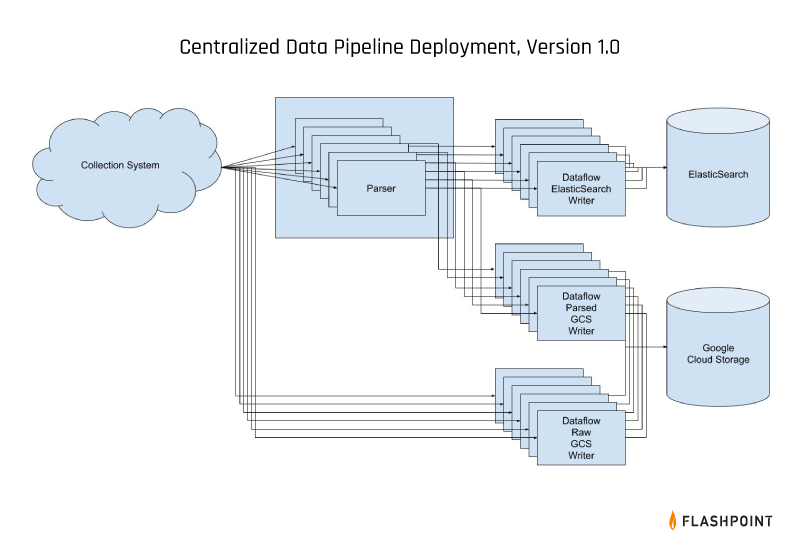
Streaming v1.0
We chose to make our updates in phases to avoid any negative operational impact. To keep things simple and straightforward, we built out a simple Beam job which read from a single PubSub subscription containing the data from one dataset and then wrote that data to an Elasticsearch index. After thorough testing we created new subscriptions on our production topics and a Dataflow job reading from each, decommissioning the old jobs as we went.
With our one-VM-running-Python-per-dataset pipelines effectively replaced by one-Dataflow-job-per-dataset pipelines, we were in a somewhat awkward position: While our infrastructure was centralized in a single team, the pipelines themselves were separate.
What this means is that individual teams were slower to iterate when it came to deploying new datasets, but we had yet to see any of the promised benefits of the transition. That being said, our new pipeline was faster and we had a much clearer idea of the overall amount of data that we were processing. Furthermore, our data centralization meant that we could track all of our different datasets more reliably. It wasn’t ideal, but it was serviceable, especially with only a few datasets to maintain.
Data enrichments provide immediate value
Our new data pipeline provided us with the opportunity to begin transforming our data. When we collect our data we collect individual messages, as well as information about the users and sites they are posted on.
We store this data separately, but when it comes to displaying that information, we want to ensure that the individual posts are properly correlated with their respective sites, users, and any other pertinent data that would help to classify our collections. To facilitate this, our individual messages have URIs to provide links between those messages and their associated data. Before writing to Elasticsearch, we wanted to join the incoming messages with the most up-to-date version of that additional data.
Denormalization
To that end, we implemented a denormalization stage in our Elasticsearch writer pipeline. This transformation would read the URIs, the intended behavior associated with each URI, and a path within the message to which we would apply the behavior. So for example, we might say to “embed” the data stored in the URI to the “site” field in the document we were processing. To start with, we were storing this metadata in Google Cloud Storage since it was the most cost-efficient option that we found. The transformation would iterate over all URIs in a document, embedding and replacing fields with the separately stored information as specified.
Unfortunately, we soon encountered an issue.
The metadata was frequently being collected around the same time as the messages we were processing. This meant that if the process for writing the metadata to GCS took longer than the process for denormalizing and writing to Elasticsearch, then we ran the substantial risk of embedding outdated information or possibly failing to embed outright.
Trial and error: Implementing an effective strategy
Initially, we tried adding retries to the denormalization stage but this caused delays to the entire pipeline, and could have resulted in backlogs that would either become insurmountable or would strain our Elasticsearch cluster. We also tried a dead lettering strategy, but that involved a manual intervention to trigger reprocessing the data, which led to unacceptably long delays in ingesting it. Furthermore, due to the ephemeral nature of the data that we were collecting, we couldn’t guarantee that any one piece of metadata would ever actually be collected.
With these issues in mind, we decided it was preferable to have the incomplete documents available rather than leave them missing due to their lack of metadata. Eventually, we settled on a temporary solution where we would replay messages after about an hour, giving us the confidence that all available metadata could be written to GCS during that time period.
With that fix in place, we had the time to refactor our denormalizer logic, switching from GCS to BigTable for our storage. BigTable has proven to be much more efficient at storing the necessary metadata in a timely manner.
Scaling challenges
Though our pipeline with the denormalization logic shared a codebase and was consistent across all of our datasets, we were still deploying separate individual pipelines. When we originally deployed this architecture we had maybe four or five pipelines loading data into Elasticsearch. Not ideal, but manageable for our small but growing Data Engineering team.
As we began to push for more varied datasets, that number rapidly expanded—we added multiple datasets over just a few weeks and our data engineering team spent most of their time configuring new pipelines and their surrounding infrastructure.
Data engineers were manually setting up new infrastructure and pipeline components for each new dataset. This was manageable when we were adding one dataset per quarter, but at multiple datasets per week, it quickly became clear that we couldn’t keep this up. The rapid increase in big data pipelines began to affect the performance and reliability of Elasticsearch, leading our SRE team to spend more of its time on scaling up the cluster, rebalancing shards, and reindexing. Additionally, all these new pipelines began to significantly increase our cloud costs.
It was the time to move on to the next stage: Creating a single unified pipeline across datasets.
Unified streaming: Finding the sweet spot
There were two major factors we had to address in order to support a unified data pipeline: 1) multiple inputs and 2) multiple outputs.
Solving for multiple inputs
First, we had individual PubSub topics per dataset coming into our data pipeline; this was necessary with individual pipelines because we had to keep that data independent. If we wanted to rapidly transition from multiple pipelines to one, the easiest solution was to modify our job to support an arbitrary number of PubSub topics as potential inputs, which we would then combine and treat as a single input.
Easy enough using Beam’s built-in Flatten transformation, but once we had all of our data coming through a unified pipeline, we then had to face the prospect of separating it back out again into the individual locations where it was stored. Fortunately, each dataset had a well-defined JSON Schema associated with the messages.
Solving for multiple outputs
Rather than statically inserting all incoming data into whatever index we manually specified, we modified our Elasticsearch writer Beam job to dynamically determine the index to which the data belonged, and write appropriately for each individual incoming message. (This also had the added benefit of enforcing a common naming convention for our indices, and for our other data stores.)
With these changes made and deployed, we were able to reduce the number of running Dataflow jobs from 50 or so to about 4. Each job was able to scale dynamically with the throughput of data from the various PubSub subscriptions from which it was reading, meaning that we were now using the minimum number of necessary worker machines at any given time instead of at least one worker per job per dataset.
This autoscaling was extremely helpful from a cost standpoint, but it did end up having a downside when it came to communicating with Elasticsearch. We discovered that there were not many options for throttling the throughput on our Elasticsearch writer, meaning that if we got a massive flood of data at a certain point, we would end up scaling out our pipeline and overwhelming our Elasticsearch cluster.
After some tuning, we found a sweet spot with a reasonable maximum number of workers for our Elasticsearch writer job, ensuring that we would not overwhelm the cluster but also that our data would still be able to get into our system in a timely manner (within 15 minutes for 95% of streaming data).
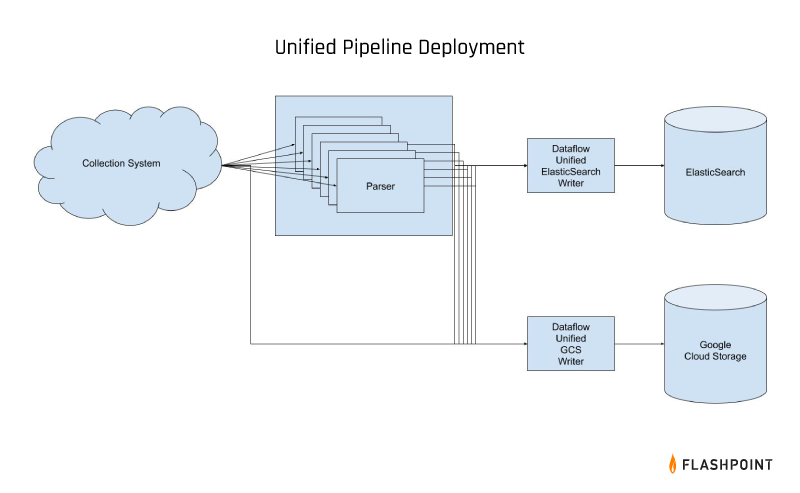
We finally had our initial unified pipeline—cost-effective, easy to maintain, and complete with a design that would allow us to operate over multiple datasets at once with a single codebase, while also differentiating between those datasets for certain operations when necessary. The major transition was out of the way, and the cost-related fires were put out. This gave us the time to automate the process of adding new datasets to further reduce the workload on our data engineering team.
Free of many of the tedious and time-sensitive tasks that were previously required of us, the data engineering team could look towards the future yet again.
Enrichments
We began by focusing on the “Transform” portion of our ETL pipeline. An opportunity soon arose when we reached out to our fellow engineers as well as Flashpoint’s product managers. Together we discovered that there was a very specific type of query that our customers were performing within the platform that was causing considerable strain on our Elasticsearch cluster.
These queries were searching for a list of numbers but due to how we were storing the data and handling the searches, they were being performed over the full text of our documents. We quickly determined that it would be relatively easy to extract the results that our customers wanted from the raw text, allowing for queries to be run much more efficiently. In the interest of separating our loads and transforms, we decided to create a new Dataflow job for these enrichments. Having separate enrichment and writing jobs also allowed us to add new data stores in parallel with enrichment development.
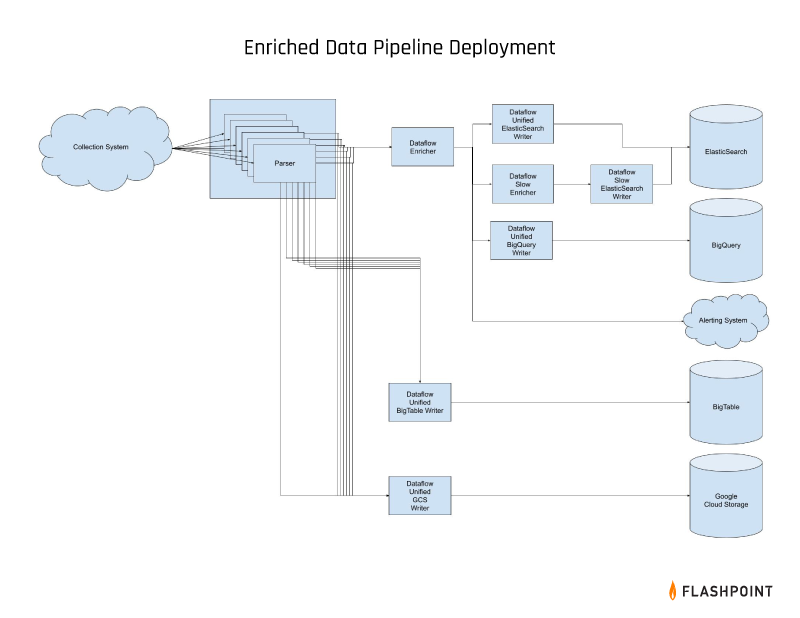
We began by creating a variety of enrichments which we would extract via regex, verify the results using enrichment-specific logic, and then add that enrichment to the base document.
As we developed our new enrichment pipeline, we came to realize that our denormalization stage was really just a complicated enrichment—and that we would benefit from certain enrichments running before denormalization and others running after—so we migrated that logic to our new enrichment job. We also developed utility enrichments to ensure that datasets had certain common fields for our UI’s usage—namely the date that we first observed a document and the date by which we want to sort any given document in the UI. (Presumably, API users would want to use that field by default as well).
These common fields allowed us to add BigQuery as an additional data store and gave us the ability to perform analyses across multiple datasets. Finally, we had a number of fields in our documents that were remnants of the collection process and wholly irrelevant to any end users (not to mention taking up space in our data stores). We created an end stage in our pipeline to remove those fields before the documents were sent to our user-facing data stores.
Where do we go from here?
We now have a scalable, performant, and cost-efficient ETL pipeline writing to multiple data stores with the ability to easily add transformations as new use cases come in. So where do we go from here?
What if we have an enrichment that is highly valuable to us but slow to run? What if we want the data from it but we don’t want to delay the message on its way to the data store, or potentially cause a roadblock in the pipeline?
The answer we’ve come to as a team is that we need to create a separate pathway for our “slow” data—one that is enriched as we get to it and doesn’t delay the base message from getting to our data stores and therefore our customers.
Join Flashpoint’s Engineering Team!
Flashpoint is hiring for a variety of exciting engineering positions. Apply today and learn why 99% of Flashpoint employees love working here, helping us become a Great Place to Work-Certified™ Company for 2021.